On Intellectual Humility: Post-Mortem of the Polls and Models
by meep
Last time I looked at predictions, I was taunting losers, and congratulating winners. The loser list was long, but the winners were the LATimes poll and two professors with non-poll-based models.
I can explain my own thoughts re: predicting the election. Obviously, I didn’t say anything at this blog, but I have been part of the Good Judgment Project, and had put in a prediction in February.
meepbobeep made a forecast:
30% A Democrat
60% A Republican
10% Other
That was before Trump won the Republican nomination, but it was pretty clear whoever the Repubs put up would be against Hillary Clinton. But notice I have a relatively high probability for “other”.
I ratcheted the probability down a little after I knew it would be Trump, but I still gave him edge. And then I forgot about my prediction for months.
I told some people about the GJP and then realized I had a prediction going on. At the time, the consensus was that Clinton would win, and I thought she would win at that point as well. So I changed it to one more favorable to the Dems:
60% A Democrat
39% A Republican
1% Other
Someone took exception to my prediction (no clue in which direction) — but at the time I made it, I was giving Trump a much higher probability of win than the pollsters, etc. And definitely higher than the consensus prediction by the GJP people. My assumption is that the person taking exception thought I gave Trump too high a probability. (Oddly, that person didn’t put in a prediction.)
Why did I give Trump such a “high” win probability? Did I know what was coming?
No. I didn’t. And that’s partly why I made such an “uncertain” prediction. Obviously, I have no special knowledge of politics (other than in the realm of public pensions, and even there, I know I’m missing some info.) But my point was that I thought the win probability for Trump others were given seemed too low given uncertainty.
So sure, I gave the edge to the Dems, but gave Trump a larger chance of winning.
One other reason is that the GJP gives one a boost if: you’re biased toward the correct direction of where the answer ended up [not surprising] and you deviate from the average prediction by a bit. So I decided to deviate from the norm in the Trump direction. I definitely didn’t feel the group was underestimating Clinton’s probability of a win.
AT LEAST ONE ELECTION PROMISE FULFILLED
WATCH: Pollster who guaranteed a Trump loss follows through on promise to eat more than his words
It is totally over. If Trump wins more than 240 electoral votes, I will eat a bug. https://t.co/3eefhWzI3y
— Sam Wang (@SamWangPhD) October 19, 2016
Ha, I like that he changed his avatar.
So, guess what. No, it wasn’t just the twitter avatar change.
He ate that bug.
Gourmet-style crickets? Jeez.
Should’ve made him eat a worm, though worms aren’t bugs (SCIENCE!)
DIFFICULTY OF PREDICTIONS
Why you couldn’t model a Trump win:
We’re doing the rounds at the Web Summit in Lisbon, trying to get a response from the tech industry on why their high-tech algos, which were supposed to be able to see you coming, failed to pick up on the sentiment that drove the Donald Trump win.
Here’s what one prominent New-York based VC told us on the sidelines of the conference:
You can’t model emotions. At the end of the day people had to walk into a booth, in secret and I think it’s really really hard to model that… modeling works very well when you have a long series of repeatable events, like credit card transactions. You can get a pretty good sense of what’s going to happen the next day, or market data. You can back test that. The reason you can’t model a Brexit, however, is because it’s a one off thing and there was no Brexit data that comes before it. There’s no data you can collect to model this one time thing. The problem with presidential elections is that they happen once in four years. And the data hasn’t been around long enough.
I suppose. Thing is, there was a huge amount of uncertainty in the polls. I don’t think it was the case that people said they would vote for Clinton and then switched to Trump (yes, I know there must have been at least a few people who did that, but I don’t think this was widespread.)
I think there were loads of people who either thought they wouldn’t vote or would vote third party, and then changed their minds. That’s a bit different.
But we’ve got stuff like this in the insurance biz. We know that customers aren’t totally rational in many dimensions, risk-taking being one of them. Some of this can be emotion-driven, and insurers don’t only go and ask what the customers want… knowing that if the insurers took people at their word, they’d go insolvent.
Likewise, pollsters know about humans. They know humans can lie.
A POLLSTER WHO GOT IT RIGHT
I missed these pollsters, as did many others: Trafalgar Group.
They got it quite right.
This piece is from a week ago — a day before the election.
Pollster Says Donald Trump Ahead in Pennsylvania, Michigan
Donald Trump is two points ahead of Hillary Clinton in the critical state of Pennsylvania, according to a new poll from the Trafalgar Group.
Trump is at 48.4 percent, she is at 46.5 percent, according to the poll from the little-known polling firm, which is also spotlighting evidence that Trump has hidden support from an additional 3 percent to 9 percent of voters who don’t want to reveal their true opinions.Breitbart News asked Trafalgar’s CEO why readers should trust the firm’s predictions amid so many other polls that show Trump lagging Clinton by 2 percent in the critical state.
“On Wednesday, I’m either going to be guy who got it right, or nobody is going to listen to me any more,” responded company CEO Robert Cahaly. “That’s why … [and] I take this craft seriously,” he told Breitbart News. In effect, the company is betting its future by publicly testing — at its own expense — its own methods.
Boy, I bet they get a lot of business now. They are promoting the heck out of their performance.
Here’s the key bit from the Breitbart piece [again, from before the election]:
He keeps his questionnaires limited to a minute or two, relies mostly on computer-delivered phone questionnaires and he probes for hidden preferences by asking people who their neighbors are supporting. That question about neighbors allows respondents to present their preferences as the opinion of others, so minimizing possible fear of stigma or embarrassment for supporting Trump.
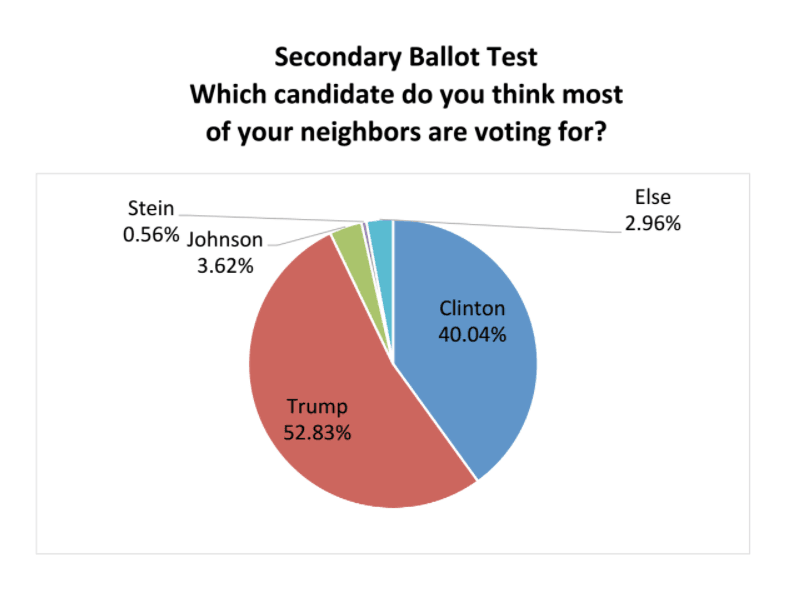
[that was the result from Pennsylvania]
Pollsters have known for a long time that people may lie about sensitive subjects. This has been an issue they’ve thought about with regards to HIV status and drug use. All sorts of techniques have been devised, but one basic one (if it’s only about opinion) is to ask what you think your neighbors or some other people will do.
It’s sad, but it’s the old technique of “some say…” when the “some” is what the author themselves wants to say, but doesn’t want to own.
Some say you can get at people’s real opinions that way.
Can’t get at my opinion that way, mainly because I’ll either tell you what I think or I won’t. I have shared the opinions I want to share online. You can ask me about other stuff, but I generally won’t answer.
ANOTHER NON-POLL PREDICTION: CORRECT
I missed this prediction from March 2016:
Trump and Sanders Test Economic Model Predicting a G.O.P. Win
If this were anything like a normal year, the Republicans would be favored to take the White House. That, at least, is what Ray Fair’s economic model has been saying consistently since November 2014.
Mr. Fair, a professor of economics at Yale and the author of “Predicting Presidential Elections and Other Things,” also says his model may well be wrong about this election. “Each election has weird things in it, yet the model usually works pretty well,” he said. “This year, though, I don’t know. This year really could be different.”
Professor Fair has been tracking and predicting elections in real time since 1978 with a good deal of success, using an approach that continues to be provocative. He ruthlessly excludes nearly all the details that are the basic diet of conventional political analysts — items like the burning issues of the day, the identities, personalities and speeches of the candidates and the strength of their campaign organizations. In fact, his model pays no attention whatsoever to the day-to-day fireworks of the political campaigns.
Instead, he considers only economics, finding that economic factors usually correlate well with political outcomes. Using two open-source econometric models that he posts on his website, he first estimates the strength of the economy. He uses that economic analysis to predict the popular vote for the two main parties, the Democrats and the Republicans. He comes up with his first estimate two years before the presidential election and provides updates at regular intervals.
…..
In November 2014, he did his first projection for the 2016 election and found that the odds favored the Republican candidate — whoever that may be. The Republican side has been leading consistently ever since, and the margin has increased as he has fed in new data.
Ray Fair’s site is here: https://fairmodel.econ.yale.edu/, with his predictions here.
His model gave increasing probability for a Republican win.
So that goes to three non-presidential polling models predicting a Republican win, and all three were correct. These are all regression models, as far as I can tell, and all outperformed the poll-based predictions. Just a thought.
EXCUSES FOR BAD RESULTS
So there’s been a lot of excuses and explanations being thrown around.
I’ll start off with Nate Silver, because though he was wrong, he was less wrong than Dr. Wang above.
Why FiveThirtyEight Gave Trump A Better Chance Than Almost Anyone Else
A small, systematic polling error made a big difference
Clinton was leading in the vast majority of national polls, and in polls of enough states to get her to 270 electoral votes, although her position in New Hampshire was tenuous in the waning days of the campaign. So there wasn’t any reasonable way to construct a polling-based model that showed Trump ahead. Even the Trump campaign itself put their candidate’s chances at 30 percent, right about where FiveThirtyEight had him.
But people mistake having a large volume of polling data for eliminating uncertainty. It doesn’t work that way. Yes, having more polls helps to a degree, by reducing sampling error and by providing for a mix of reasonable methodologies. Therefore, it’s better to be ahead in two polls than ahead in one poll, and in 10 polls than in two polls. Before long, however, you start to encounter diminishing returns. Polls tend to replicate one another’s mistakes: If a particular type of demographic subgroup is hard to reach on the phone, for instance, the polls may try different workarounds but they’re all likely to have problems of some kind or another. The cacophony of headlines about how “CLINTON LEADS IN POLL” neglected the fact that these leads were often quite small and that if one poll missed, the others potentially would also. As I pointed out on Wednesday, if Clinton had done only 2 percentage points better across the board, she would have received 307 electoral votes and the polls would have “called” 49 of 50 states correctly.
…..
FiveThirtyEight’s models consider possibilities such as these. In addition to a systematic national polling error, we also simulate potential errors across regional or demographic lines — for instance, Clinton might underperform in the Midwest in one simulation, or there might be a huge surge of support among white evangelicals for Trump in another simulation. These simulations test how robust a candidate’s lead is to various types of polling errors.…..
Undecideds and late deciders broke for TrumpThe single most important reason that our model gave Trump a better chance than others is because of our assumption that polling errors are correlated. No matter how many polls you have in a state, it’s often the case that all or most of them miss in the same direction. Furthermore, if the polls miss in one direction in one state, they often also miss in the same direction in other states, especially if those states are similar demographically.
There were some other factors too, however, that helped Trump’s chances in our forecast. One is that our model considers the number of undecided and third-party voters when evaluating the uncertainty in the race. There were far more of these voters than in recent, past elections: About 12 percent of the electorate wasn’t committed to either Trump or Clinton in final national polls, as compared with just 3 percent in 2012. That’s a big part of the reason our model was quite confident about Obama’s chances in 2012, but not all that confident about Clinton’s chances this year.
That 12% undecided is huge.
Now, it may be that many people really were undecided. It could be that Comey’s Hokey Pokey decided them.
It could also be that they were lying about being undecided.
Either way, that’s a huge amount of uncertainty when there’s a close race. In New York, where I live, 12% undecided won’t do crap. We know the Democrat is going to win.
But in Pennsylvania?
Yeah.
BLAMING THE POLLS
Here’s one person blaming the pollsters:
It is imperative to note that the most conservative leaning pollsters this year (and this applies as well in previous elections) should be congratulated for being the least irresolute in their polling strategy and predictive results (each one oscillating their polling estimate ~2% throughout the season, and very tight amongst on another). At times IBD or Rasmussen were lambasted for being alone in showing Trump in a close race, but when the FBI reopened the e-mail probe into Hillary’s e-mails, suddenly in recent days they looked like virtuosi among other “discouraged” pollsters. Discouraged because they were once again wrong, or depressed because the heavily favored now suddenly waning Hillary?
The more liberal pollsters (e.g., USAToday) again had overly wild variations in their methodology and their sensitivity to and transmission of news into election probabilities this season (each one oscillating their polling estimate ~3-4% throughout the season, and very disparate amongst one another). See the article linked above for rationales as to why such flip-flopping by pollsters should be cause for scorn among Americans. We deserve far better than personal partisanships mixing with polling news, and in the coming years it wouldn’t be a shock to see such ill-performing polling outfits garner less consideration (even in “averages among polls” which we will argue must deliberate variation in error as much as merely bias). These latter liberal pollsters produced the most faux disturbance for ordinary Americans, even in the unlikely event that their combined estimated spread of >5%, both disorderly and unintentionally, emanates as anywhere close to true on election night. After all, those prayers worked out so well for the recent, #BrexitRemain and #NeverDrumpf festivals.
The author of the above wrote this analysis pre-election, which is quite interesting for the stats nerds. There was an indication something was wrong with the polls ahead of time. But people didn’t want to hear it.
A CALL FOR INTELLECTUAL HUMILITY
It won’t kill you to say “I don’t know” when you don’t know.
It also helps to explicitly look for info against your preferred result or anticipated result. There’s this thing called confirmation bias, which seems to have run rampant among pollsters and media people using the polls. It’s not merely interpreting new info as supporting your desired result, but that you’re not actively looking for disconfirming evidence. People didn’t want to see that Trump may have had a chance, so they never saw it coming.
Nate Silver’s models worked okay. Those who allowed in uncertainty and considered that Clinton wasn’t a lock had the chance of seeing that there may be negative info in what they were looking at.
The people who were predicting a 90%+ chance for Clinton to win were indulging in a hubris…. which often ends in nemesis.

Oh boy, does it.
As I said last Wednesday, I didn’t find the election results shocking (mainly because I knew there were a bunch of question marks hovering over the midwest), but I did find them surprising. After all, my last prediction gave an edge to the Dems. I was wrong.
Likewise, I really have no clue what Trump’s going to do.
So I’m not even going to predict at this point.
Of course, people who say “I don’t know” don’t get invited to be talking heads on TV, but given how I look, that wasn’t really in the cards, either.
Still, I’d rather say “I don’t know” than pretend I do know when I don’t.
Related Posts
Labor force participation rates, part 4: Old v. Young
Meep and Media: Podcasts and Videos - Sumo, Fraud, and Math, oh my!
Labor force participation rates, part 3: Older folks (55 and up)
